
Potencializando o
Agronegócio
Através dos Dados
Conectamos dados, automatizamos processos e geramos inteligência para otimizar a gestão no setor agropecuário.

Somos ISO 27001!
Padrão internacional de segurança da informação
Obter a certificação ISO 27001 nos conferiu uma série de vantagens significativas, e elas vão além do prestígio de conquistar um selo internacionalmente reconhecido:
Nossas Soluções
Automação e inteligência
para o agronegócio


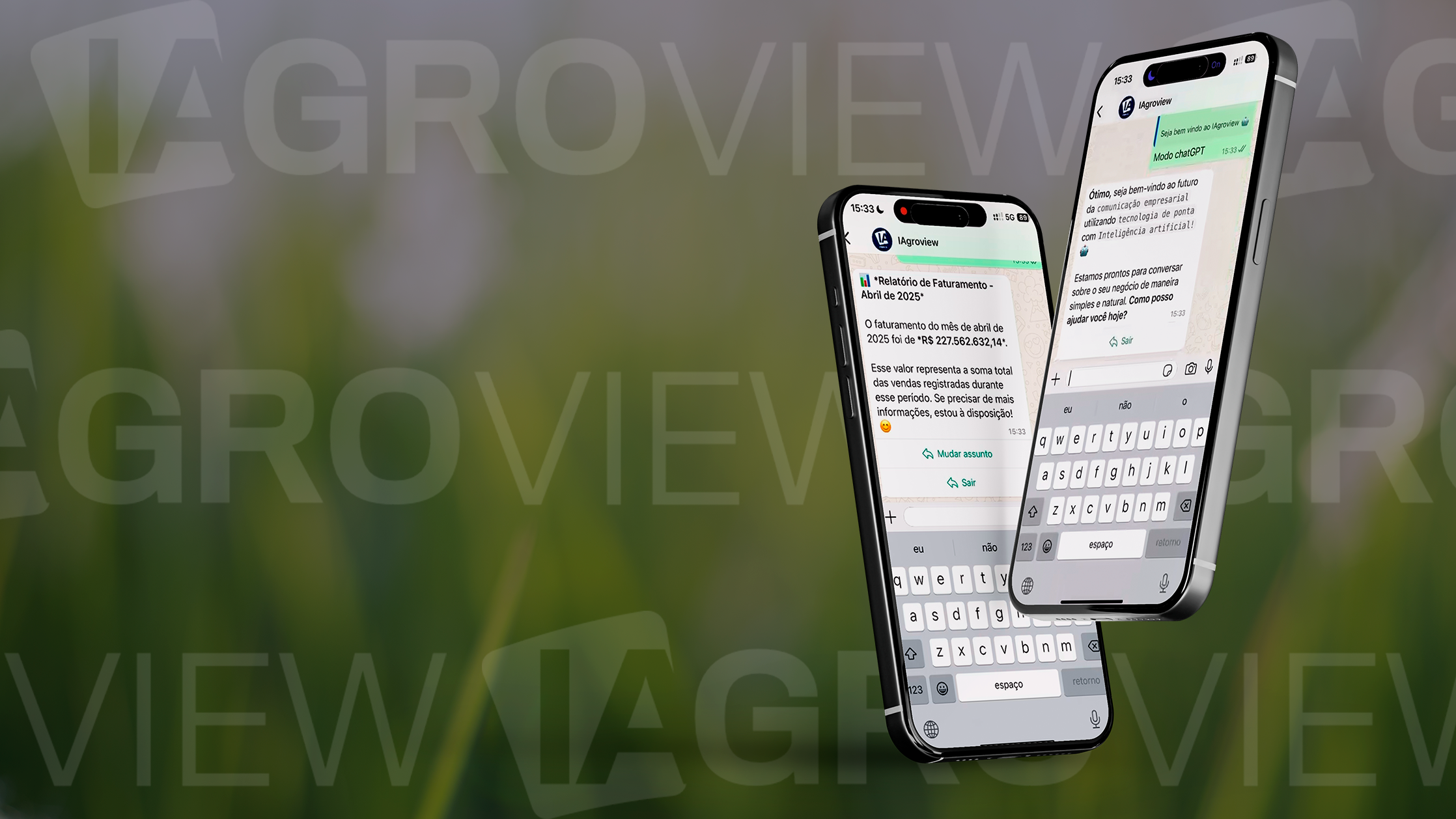
O Agroview é a solução de Business Intelligence (BI) da BRID, desenvolvida especialmente para empresas do agronegócio que buscam tomar decisões melhores no seu dia a dia. Com informações baseadas em dados confiáveis, integrados e atualizados do seu negócio, o Agroview oferece análises estratégicas, painéis de controle e indicadores de performance, permitindo uma visão completa e em tempo real do seu negócio.


O Agrofortis é a solução de CRM (Customer Relationship Management) da Brid, desenvolvida especialmente para atender às necessidades do agronegócio. Com ele, distribuidores, revendas e indústrias do setor podem gerenciar suas equipes comerciais, acompanhar oportunidades de venda e fortalecer o relacionamento com clientes, tudo em uma única plataforma inteligente.


Nossa consultoria é especializada na gestão do agro, dados e tecnologia para evoluir seus processos, profissionalizar a tomada de decisão, alcançar novos níveis de performance e potencializar seus resultados.
Nossa missão é clara: ajudar sua empresa a vender mais, comprar melhor, planejar com precisão e crescer com inteligência.



A Zyon é a plataforma de Big Data com foco exclusivo no agronegócio brasileiro que vai levar sua empresa ao próximo nível.
Por meio de inteligência artificial e integração de dados públicos, ela transforma informação em estratégia, revelando mercados, clientes e oportunidades que antes estavam invisíveis para o seu negócio. Tudo em um só lugar.
TECNOLOGIAS









Nossa Abordagem
A Jornada da
Inteligência em Dados

Integramos diferentes fontes de informação, como ERPs, planilhas e dados de mercado.

Utilizamos Data Warehouses, Data Lakes e Data Lakehouses.

Aplicamos Business Intelligence e Analytics para gerar insights estratégicos.

Criamos relatórios e dashboards intuitivos, facilitando a tomada de decisão.

Suporte contínuo para garantir que utilizem os dados de forma eficiente.

Aplicamos Business Intelligence e Analytics para gerar insights estratégicos.

A Syngenta, uma das maiores empresas globais do setor agrícola, buscava aprimorar sua estratégia de dados para otimizar a tomada de decisões e aumentar a eficiência operacional. Com desafios complexos envolvendo integração de informações, análise preditiva e insights acionáveis, a Syngenta encontrou na Brid a parceira ideal para sua transformação digital.

Nossa história começa em 2002 atendendo ao setor do agronegócio brasileiro, experiência acumulada ao longo de todos esses anos entendendo cada cliente, suprindo suas necessidades e desejos. Desde então seguimos unindo as soluções tecnológicas ao cotidiano do campo, visando tornar a informação e o conhecimento fonte de sustentação do sucesso dos negócios de nossos clientes.

O Que Nossos Clientes Dizem









BLOG
Entre em contato
Nossa equipe está sempre pronta para esclarecer suas dúvidas e ouvir suas sugestões e opiniões. Preencha o formulário ao lado ou entre em contato conosco pelas informações abaixo.
contato@bridsolucoes.com.br











